
Optical Character Recognition component
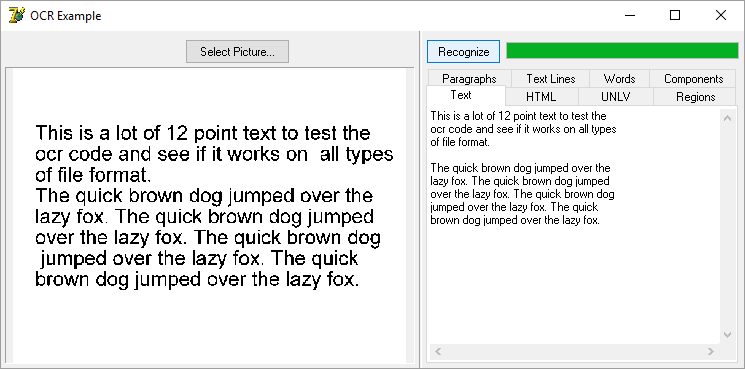
Use this OCR component to extract text from images, such as scanned paper documents or other image-based files.
- Powered by the Tesseract OCR engine and the Leptonica image processing library
- Compatible with Delphi/C++Builder versions 5 - 13, and Lazarus 4.4
- Includes source code with the registered version
- Offers royalty-free distribution for your application
Download the Tesseract language data and store them to the designated tessdata folder.
Order OCR component $100 USD (license for one developer)
Order OCR multi-license $300 USD (license for all developers in company)
Order OCR year upgrades $50 USD (registered users only)
Order OCR year upgrades multi-license $150 USD (registered multi-license users only)